ZKM Schlosslichtspiele Karlsruhe
16–08–2023







second prize
project: AI+GA Artificial Intelligence + Generative Art
production: Schlosslichtspiele ZKM Karlsruhe
The AI+GA concept is a site-specific Overlapping project for Schlosslichtspiele x ZKM.
Considering the massive projection surface w.160m, h.17m, a total amount of 16 projectors, we focused on the use of cutting edge technology to create generative art content, using mostly TouchDesigner, a node based visual programming language for real time interactive multimedia content, that allows to design high-resolution effects through scripts and complex networks.

Our design approach is to show abstract and molecular visuals. We refer to physical formulas to simulate dynamics fluids with boundary and coloured vortex. Inspired by the behaviour of atomic particles, we aim to represent real life in its elementary components.
In the interplay with the castle façade, fluids are generated from the windows, merge into clouds framing the doors, a fast, colourful smoke reacting like incompressible elements such as water or oil, blending into a colourful nebula, transforming the Schloss into a dreamlike landscape.

A tailor-made analog sound carpet underlines and emphasises the performance, holding the narrative together and creating an uninterrupted flow of visions and atmospheres. Sound engages and triggers the creation of generative art, mathematical codes and object-oriented programming to fuse together visual patterns and beautiful colours.

In the last act, we play with artificial intelligence to generate images, by using prompts and mottos keywords, to feed the software and guide it towards the target aesthetic. We craft the imaginary by smoothly switching interpolating between 2D images and the latent space generated by artificial intelligence tools, a form of motion design defined as latent dreams.
Almost all show contents is used an AI filter to up-scale x4 the resolution in ultra-high definition, created an overall unanimous hi-res look.
Almost all show contents is used an AI filter to up-scale x4 the resolution in ultra-high definition, created an overall unanimous hi-res look.

To create a cinematic finale, we interact with the architecture creating the 3D of the façade and then break it up into fragments, using kinetic forces to achieve a smooth and realistic breaking motion.






5 keywords suggested by the festival:
The future is a time of opportunities, challenges and hopes. We live in a world where social cohesion is increasingly important to manage the diversity, complexity and uncertainty that surround us. The dawn of devices is an opportunity to improve our quality of life, enhance our creativity and strengthen our connection with others. But it is also a responsibility to consider the ethical, environmental and social implications of our technological choices. Digitalisation is a process that is transforming our society by creating new ways of communicating, learning, working and living together. It opens up new horizons of hope for us, but also requires critical reflection on the risks and limits it entails. We are the architects of our future. Let us face it with enthusiasm, wisdom and solidarity.
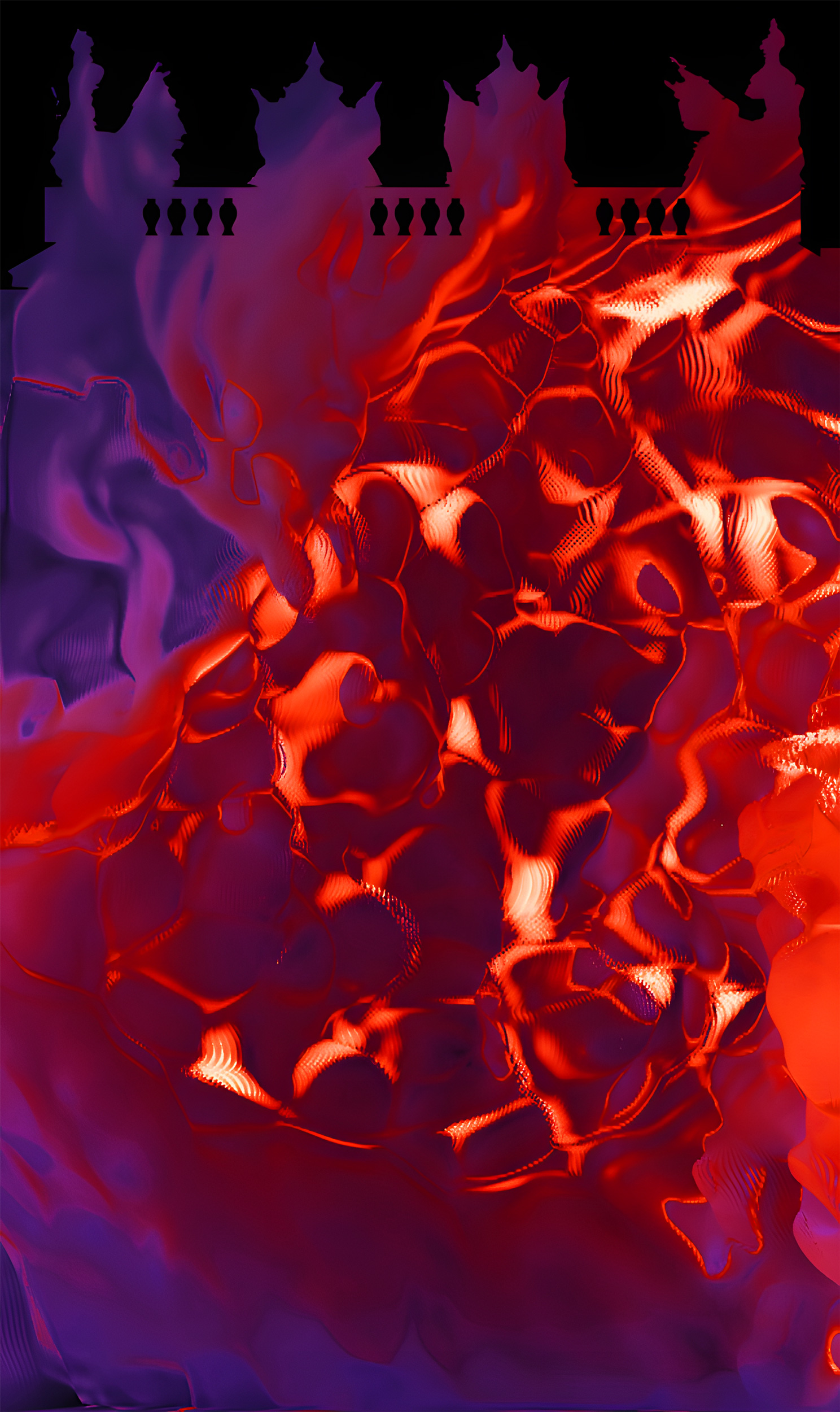
Can a machine act intelligently?
Can it solve any problem that a human being would solve by thinking?
Are human intelligence and machine intelligence the same thing? Is the human brain essentially a computer?
If a machine acts as intelligent as a human being, then is it as intelligent as a human being?
Can it solve any problem that a human being would solve by thinking?
Are human intelligence and machine intelligence the same thing? Is the human brain essentially a computer?
If a machine acts as intelligent as a human being, then is it as intelligent as a human being?


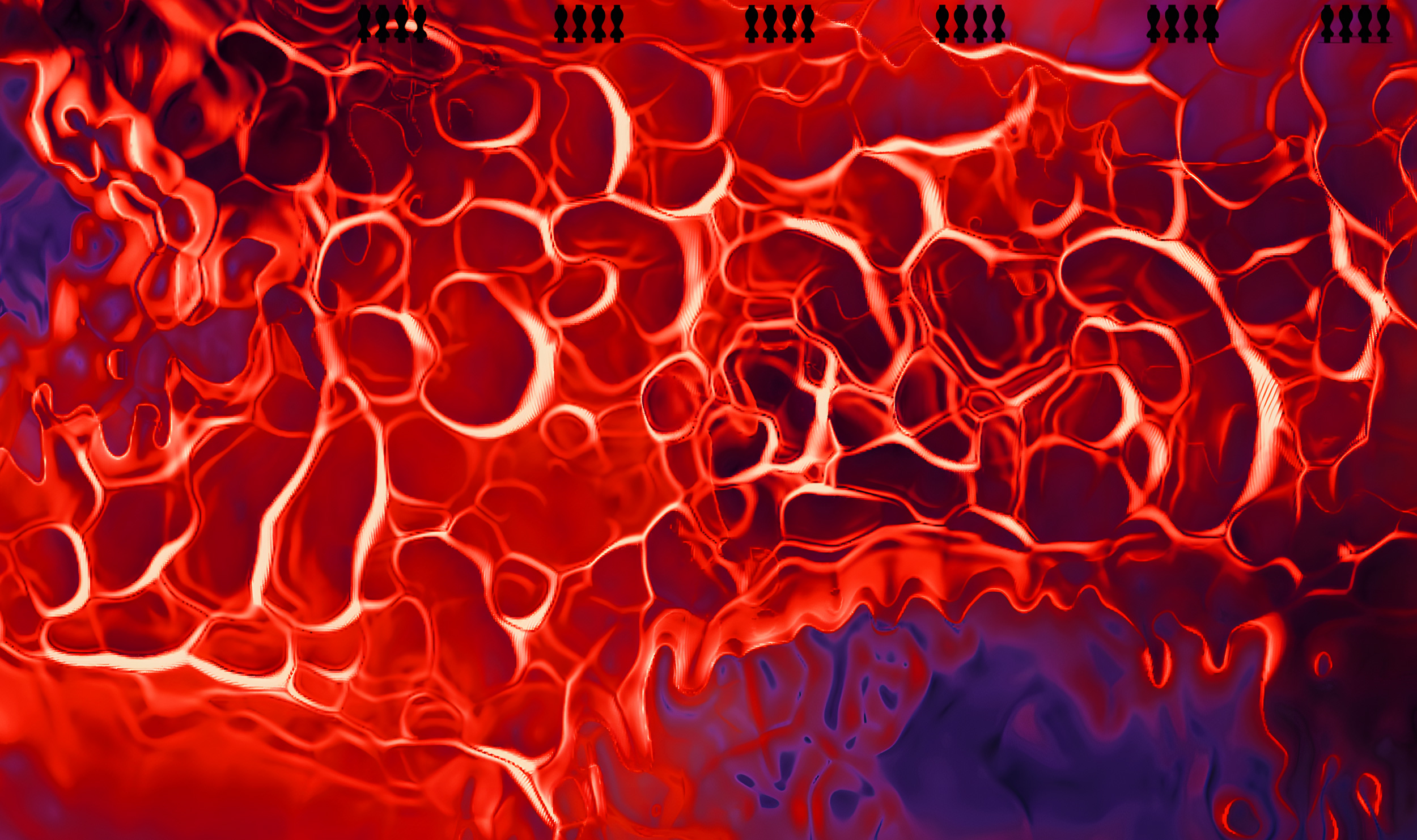


further contents, upscaled images 4x
Artificial Intelligence modus_operandi_Overlapping
Automatic1111:
For Schlosslichtspiele show, we chose automatic1111 as our platform to use and mix pre-trained AI models. We enhanced the web UI with some extensions like Deforum and the modelMerger. All these tools combined allow the user to be free and in harmony with the latent space, where human creativity is powered by the computer. To take advantage of the extraordinary power offered by Diffusion models, we carried out extensive research on prompt architecture and developed our own customised LORA weights to drive the AI exactly where we want it to be. We used a custom Stable Diffusion model created by mixing 3 open-source checkpoints (.ckpt), which were forced to be creative with various prompts, but chained, so as to generate every frame from a given image and path. Stable Diffusion is a deep learning, text-to-image model for generating realistic and diverse images from a latent space. It is primarily used to generate detailed images conditioned on text descriptions, though it can also generating image-to-image translations guided by a text prompt. It is based on the idea of gradually transforming a random noise image into a target image through a series of diffusion steps. Each step involves adding or removing some noise from the image, depending on the direction of the transformation. One of the challenges of stable diffusion is to design a suitable latent space that can represent the data well and allow for easy manipulation and interpolation. One of the most used web UI for AI image generation is automatic1111. It is known for its user-friendly interface and its ability to generate high-quality images.
How Stable Diffusion Generates Images:
To generate an image using Stable Diffusion, the model takes in a text prompt as input and then generates an image based on that description. The process starts with the text prompt being fed into the text encoder, which generates a text embedding. This text embedding is then used to condition the latent diffusion model. The main advantage of stable diffusion over other generative models is that it can produce high-quality images without collapsing to a single mode or suffering from mode dropping. This means that stable diffusion can handle complex and high-dimensional data, such as natural images, faces, and scenes.
Automatic1111:
For Schlosslichtspiele show, we chose automatic1111 as our platform to use and mix pre-trained AI models. We enhanced the web UI with some extensions like Deforum and the modelMerger. All these tools combined allow the user to be free and in harmony with the latent space, where human creativity is powered by the computer. To take advantage of the extraordinary power offered by Diffusion models, we carried out extensive research on prompt architecture and developed our own customised LORA weights to drive the AI exactly where we want it to be. We used a custom Stable Diffusion model created by mixing 3 open-source checkpoints (.ckpt), which were forced to be creative with various prompts, but chained, so as to generate every frame from a given image and path. Stable Diffusion is a deep learning, text-to-image model for generating realistic and diverse images from a latent space. It is primarily used to generate detailed images conditioned on text descriptions, though it can also generating image-to-image translations guided by a text prompt. It is based on the idea of gradually transforming a random noise image into a target image through a series of diffusion steps. Each step involves adding or removing some noise from the image, depending on the direction of the transformation. One of the challenges of stable diffusion is to design a suitable latent space that can represent the data well and allow for easy manipulation and interpolation. One of the most used web UI for AI image generation is automatic1111. It is known for its user-friendly interface and its ability to generate high-quality images.
How Stable Diffusion Generates Images:
To generate an image using Stable Diffusion, the model takes in a text prompt as input and then generates an image based on that description. The process starts with the text prompt being fed into the text encoder, which generates a text embedding. This text embedding is then used to condition the latent diffusion model. The main advantage of stable diffusion over other generative models is that it can produce high-quality images without collapsing to a single mode or suffering from mode dropping. This means that stable diffusion can handle complex and high-dimensional data, such as natural images, faces, and scenes.
Premiere on 16 August 2023
Schlosslichtspiele Karlsruhe
ZKM | Zentrum für Kunst und Medien Karlsruhe
Simone Serlenga_Media Scenography
@elenaveronesedesign Design and Concept
Simone Franco_Generative Artist+Real-time motion designer
@makoto_sakamoto_recordings Sound Design
Production_Overlapping Studio Berlin
@schlosslichtspielekarlsruhe
@zkmkarlsruhe